TL;DR: I tested a bunch of neural network architectures plus SVM + NB on several text classification datasets. Results at the bottom of the post.
Last year I wrote a post about using word embeddings like word2vec or GloVe for text classification. The embeddings in my benchmarks were used in a very crude way - by averaging word vectors for all words in a document and then plugging the result into a Random Forest. Unfortunately, the resulting classifier turned out to be strictly inferior to a good old SVM except in some special circumstances (very few training examples but lots of unlabeled data).
There are of course better ways of utilising word embeddings than averaging the vectors and last month I finally got around to try them. As far as I can tell from a brief survey of arxiv, most state of the art text classifiers use embeddings as inputs to a neural network. But what kind of neural network works best? LSTM? LSTM? CNN? BLSTM with CNN? There are doezens of tutorials on the internet showing how to implement this of that neural classfier and testing it on some dataset. The problem with them is that they usually give metrics without a context. Someone says that their achieved 0.85 accuracy on some dataset. Is that good? Should I be impressed? Is it better than Naive Bayes, SVM? Than other neural architectures? Was it a fluke? Does it work as well on other datasets?
To answer those questions, I implemented several network architectures in Keras and created a benchmark where those algorithms compete with classics like SVM and Naive Bayes. Here it is.
I intend to keep adding new algorithms and dataset to the benchmark as I learn about them. I will update this post when that happens.
Models
All the models in the repository are wrapped in scikit-learn compatible classes with .fit(X, y), .predict(X), .get_params(recursive) and with all the layer sizes, dropout rates, n-gram ranges etc. parametrised. The snippets below are simplified for clarity.
Since this was supposed to be a benchmark of classifiers, not of preprocessing methods, all datasets come already tokenised and the classifier is given a list of token ids, not a string.
Naive Bayes
Naive Bayes comes in two varieties - Bernoulli and Multinomial. We can also use tf-idf weighting or simple counts and we can include n-grams. Since sklearn’s vectorizer expects a string and will be giving it a list of integer token ids, we will have to override the default preprocessor and tokenizer.
1 2 3 4 5 6 7 8 9 10 11 | |
SVM
SVMs are a strong baseline for any text classification task. We can reuse the same vectorizer for this one.
1 2 3 | |
Multi Layer Perceptron
In other words - a vanilla feed forward neural network. This model doesn’t use word embeddings, the input to the model is a bag of words.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Inputs to this model need to be one-hot encoded, same goes for labels.
1 2 3 4 5 6 | |
(Bidirectional) LSTM
This is where things start to get interesting. The input to this model is not a bag of words but instead a sequence word ids. First thing to do is construct an embedding layer that will translate this sequence into a matrix of d-dimensional vectors.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Now for the model proper:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
This and all the other models using embeddings requires that labels are one-hot encoded and word id sequences are padded to fixed length with zeros:
1 2 3 4 5 | |
François Chollet’s CNN
This is the (slightly modified) architecture from Keras tutorial. It’s specifically designed for texts of length 1000, so I only used it for document classification, not for sentence classification.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Yoon Kim’s CNN
This is the architecture from the Yoon Kim’s paper, my implementation is based on Alexander Rakhlin’s. This one doesn’t rely on text being exactly 1000 words long and is better suited for sentences.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
BLSTM2DCNN
Authors of the paper claim that combining BLSTM with CNN gives even better results than using either of them alone. Weirdly, unlike previous 2 models, this one uses 2D convolutions. This means that the receptive fields of neurons run not just across neighbouring words in the text but also across neighbouring coordinates in the embedding vector. This is suspicious because there is no relation between consecutive coordinates in e.g. GloVe embedding which they use. If one neuron learns a pattern involving coordinates 5 and 6, there is no reason to think that the same pattern will generalise to coordinates 22 and 23 - which makes convolution pointless. But what do I know.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Stacking
In addition to all those base models, I implemented stacking classifier to combine predictions of all those very different models. I used 2 versions of stacking. One where base models return probabilities, and those are combined by a simple logistic regression. The other, where base models return labels, and XGBoost is used to combine those.
Datasets
For the document classification benchmark I used all the datasets from here. This includes the 20 Newsgroups, Reuters-21578 and WebKB datasets in all their different versions (stemmed, lemmatised, etc.).
For the sentence classification benchmark I used the movie review polarity dataset and the Stanford sentiment treebank dataset.
Results
Some models were only included in document classification or only in sentence classification - because they either performed terribly on the other or took too long to train. Hyperparameters of the neural models were (somewhat) tuned on one of the datasets before including them in the benchmark. The ratio of training to test examples was 0.7 : 0.3. This split was done 10 times on every dataset and each model was tested 10 time. The tables below show average accuracies across the 10 splits.
Without further ado:
Document classification benchmark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
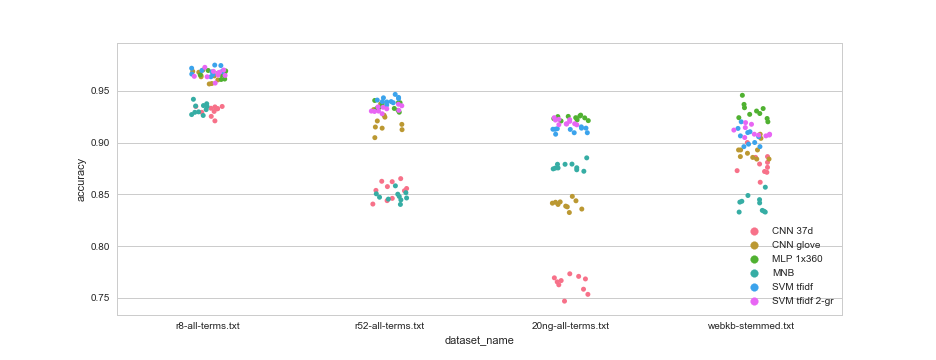
Sentence classification benchmark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
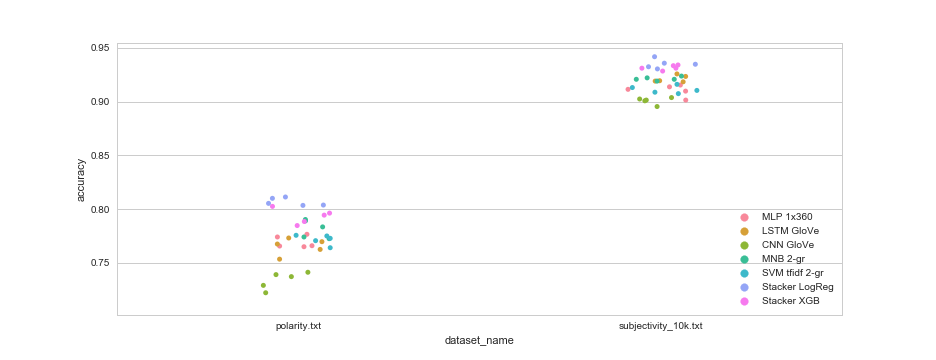
Conclusions
Well, this was underwhelming.
None of the fancy neural networks with embeddings managed to beat Naive Bayes and SVM, at least not consistently. A simple feed forward neural network with a single layer, did better than any other architecture.
I blame my hyperparameters. Didn’t tune them enough. In particular, the number of epochs to train. It was determined once for each model, but different datasets and different splits probably require different settings.
And yet, the neural models are clearly doing something right because adding them to the ensemble and stacking significantly improves accuracy.
When I find out what exactly is the secret sauce that makes the neural models achieve the state of the art accuracies that papers claim they do, I will update my implementations and this post.