Text classification with Word2Vec
In the previous post I talked about usefulness of topic models for non-NLP tasks, it’s back to NLP-land this time. I decided to investigate if word embeddings can help in a classic NLP problem - text categorization. Full code used to generate numbers and plots in this post can be found here: python 2 version and python 3 version by Marcelo Beckmann (thank you!).
####Motivation The basic idea is that semantic vectors (such as the ones provided by Word2Vec) should preserve most of the relevant information about a text while having relatively low dimensionality which allows better machine learning treatment than straight one-hot encoding of words. Another advantage of topic models is that they are unsupervised so they can help when labaled data is scarce. Say you only have one thousand manually classified blog posts but a million unlabeled ones. A high quality topic model can be trained on the full set of one million. If you can use topic modeling-derived features in your classification, you will be benefitting from your entire collection of texts, not just the labeled ones.
####Getting the embedding Ok, word embeddings are awesome, how do we use them? Before we do anything we need to get the vectors. We can download one of the great pre-trained models from GloVe:
wget http://nlp.stanford.edu/data/glove.6B.zip
unzip glove.6B.zip
and use load them up in python:
import numpy as np
with open("glove.6B.50d.txt", "rb") as lines:
w2v = {line.split()[0]: np.array(map(float, line.split()[1:]))
for line in lines}
or we can train a Word2Vec model from scratch with gensim:
import gensim
# let X be a list of tokenized texts (i.e. list of lists of tokens)
model = gensim.models.Word2Vec(X, size=100)
w2v = dict(zip(model.wv.index2word, model.wv.syn0))
The (python) meat
We got ourselves a dictionary mapping word -> 100-dimensional vector. Now we can use it to build features. The simplest way to do that is by averaging word vectors for all words in a text. We will build a sklearn-compatible transformer that is initialised with a word -> vector dictionary.
class MeanEmbeddingVectorizer(object):
def __init__(self, word2vec):
self.word2vec = word2vec
# if a text is empty we should return a vector of zeros
# with the same dimensionality as all the other vectors
self.dim = len(word2vec.itervalues().next())
def fit(self, X, y):
return self
def transform(self, X):
return np.array([
np.mean([self.word2vec[w] for w in words if w in self.word2vec]
or [np.zeros(self.dim)], axis=0)
for words in X
])
Let’s throw in a version that uses tf-idf weighting scheme for good measure
class TfidfEmbeddingVectorizer(object):
def __init__(self, word2vec):
self.word2vec = word2vec
self.word2weight = None
self.dim = len(word2vec.itervalues().next())
def fit(self, X, y):
tfidf = TfidfVectorizer(analyzer=lambda x: x)
tfidf.fit(X)
# if a word was never seen - it must be at least as infrequent
# as any of the known words - so the default idf is the max of
# known idf's
max_idf = max(tfidf.idf_)
self.word2weight = defaultdict(
lambda: max_idf,
[(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()])
return self
def transform(self, X):
return np.array([
np.mean([self.word2vec[w] * self.word2weight[w]
for w in words if w in self.word2vec] or
[np.zeros(self.dim)], axis=0)
for words in X
])
These vectorizers can now be used almost the same way as CountVectorizer or TfidfVectorizer from sklearn.feature_extraction.text. Almost - because sklearn vectorizers can also do their own tokenization - a feature which we won’t be using anyway because the benchmarks we will be using come already tokenized. In a real application I wouldn’t trust sklearn with tokenization anyway - rather let spaCy do it.
Now we are ready to define the actual models that will take tokenised text, vectorize and learn to classify the vectors with something fancy like Extra Trees. sklearn’s Pipeline is perfect for this:
from sklearn.pipeline import Pipeline
from sklearn.ensemble import ExtraTreesClassifier
etree_w2v = Pipeline([
("word2vec vectorizer", MeanEmbeddingVectorizer(w2v)),
("extra trees", ExtraTreesClassifier(n_estimators=200))])
etree_w2v_tfidf = Pipeline([
("word2vec vectorizer", TfidfEmbeddingVectorizer(w2v)),
("extra trees", ExtraTreesClassifier(n_estimators=200))])
Benchmarks
I benchmarked the models on everyone’s favorite Reuters-21578 datasets. Extra Trees-based word-embedding-utilising models competed against text classification classics - Naive Bayes and SVM. Full list of contestants:
- mult_nb - Multinomial Naive Bayes
- bern_nb - Bernoulli Naive Bayes
- svc - linear kernel SVM
- glove_small - ExtraTrees with 200 trees and vectorizer based on 50-dimensional gloVe embedding trained on 6B tokens
- glove_big - same as above but using 300-dimensional gloVe embedding trained on 840B tokens
- w2v - same but with using 100-dimensional word2vec embedding trained on the benchmark data itself (using both training and test examples [but not labels!])
Each of these came in two varieties - regular and tf-idf weighted.
The results (on 5-fold cv on a the R8 dataset of 7674 texts labeled with 8 categories):
model score
----------------- -------
svc_tfidf 0.9656
svc 0.9562
w2v_tfidf 0.9544
w2v 0.9510
mult_nb 0.9467
glove_big 0.9274
glove_small 0.9262
glove_small_tfidf 0.9075
glove_big_tfidf 0.9038
mult_nb_tfidf 0.8615
bern_nb 0.7954
bern_nb_tfidf 0.7954
SVM wins, word2vec-based Extra Trees is a close second, Naive Bayes not far behind. Interestingly, embedding trained on this relatively tiny dataset does significantly better than pretrained GloVe - which is otherwise fantastic. Can we do better? Let’s check how do the models compare depending on the number of labeled training examples. Due to its semi-supervised nature w2v should shine when there is little labeled data.
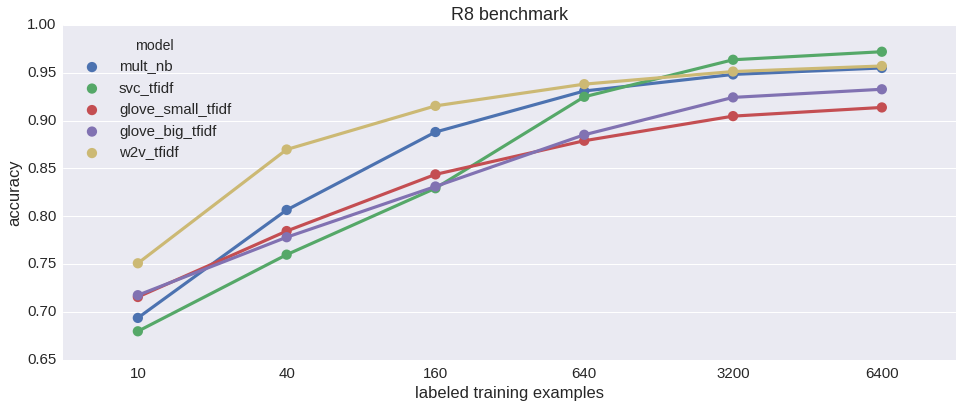
That indeed seems to be the case. w2v_tfidf’s performance degrades most gracefully of the bunch. SVM takes the biggest hit when examples are few. Lets try the other two benchmarks from Reuters-21578. 52-way classification:
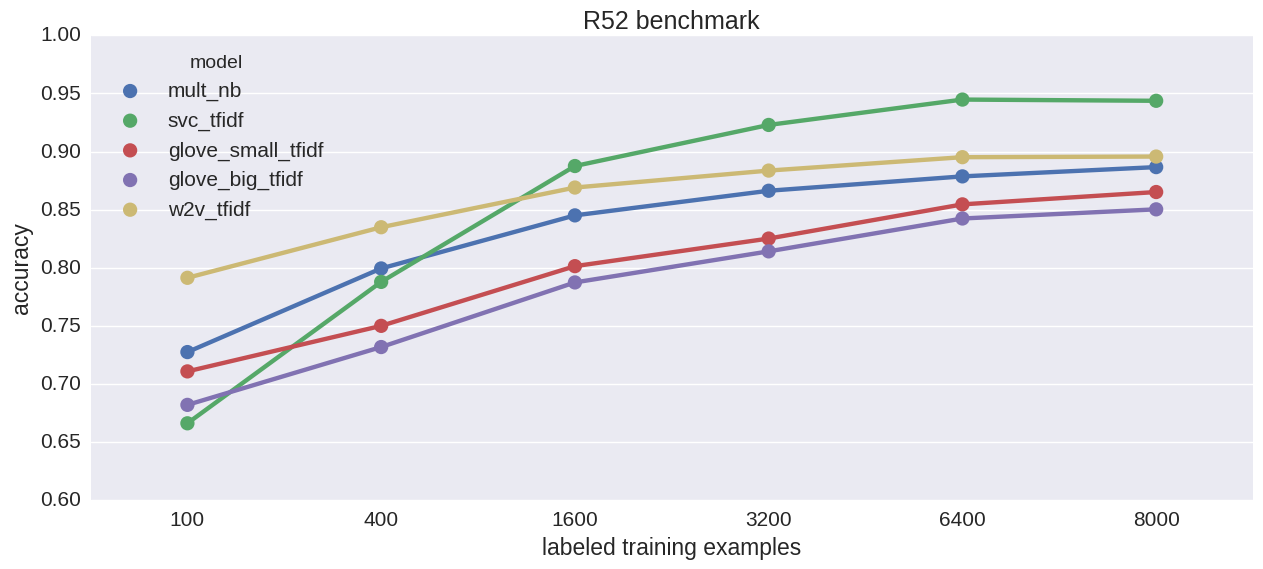
Qualitatively similar results.
And 20-way classification:
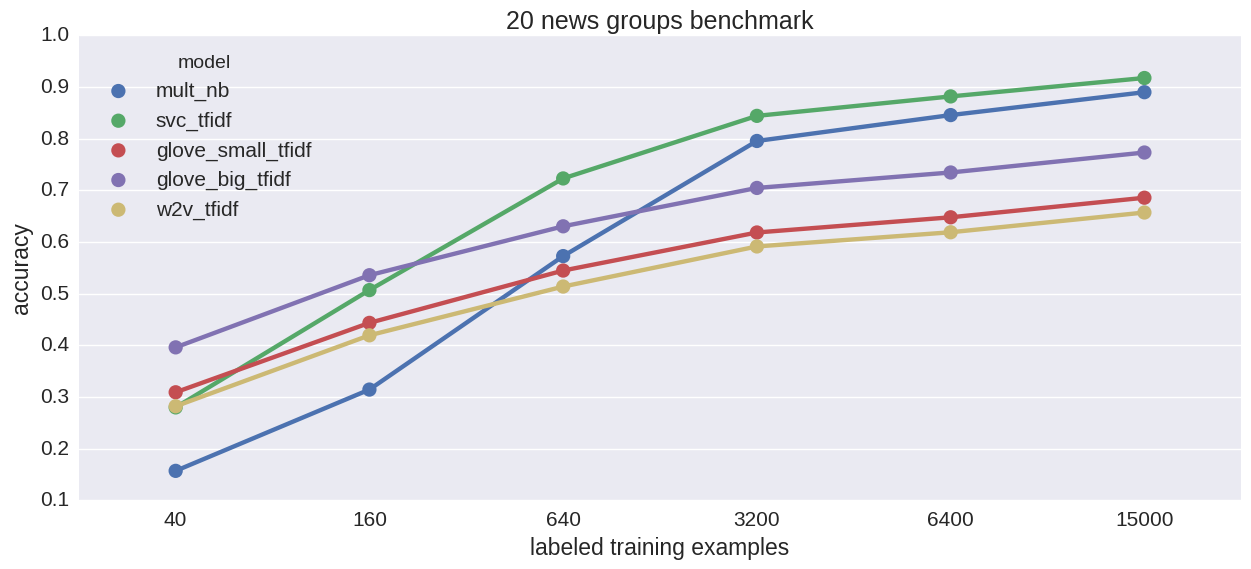
This time pretrained embeddings do better than Word2Vec and Naive Bayes does really well, otherwise same as before.
####Conclusions
- SVM’s are pretty great at text classification tasks
- Models based on simple averaging of word-vectors can be surprisingly good too (given how much information is lost in taking the average)
- but they only seem to have a clear advantage when there is ridiculously little labeled training data
At this point I have to note that averaging vectors is only the easiest way of leveraging word embeddings in classification but not the only one. You could also try embedding whole documents directly with Doc2Vec. Or use Multinomial Gaussian Naive Bayes on word vectors. I have tried the latter approach but it was too slow to include in the benchmark.
Update 2017: actually, the best way to utilise the pretrained embeddings would probably be this https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html I shall add this approach to the benchmark when I have some time.
- Sometimes pretrained embeddings give clearly superior results to word2vec trained on the specific benchmark, sometimes it’s the opposite. Not sure what is going on here.
Overall, we won’t be throwing away our SVMs any time soon in favor of word2vec but it has it’s place in text classification. Like when you have a tiny training set or to ensemble it with other models to gain edge in Kaggle.
Plus, can SVM do this:
X = [['Berlin', 'London'],
['cow', 'cat'],
['pink', 'yellow']]
y = ['capitals', 'animals', 'colors']
etree_glove_big.fit(X, y)
# never before seen words!!!
test_X = [['dog'], ['red'], ['Madrid']]
print etree_glove_big.predict(test_X)
prints
['animals' 'colors' 'capitals']
Comments